

809 字
4 分钟
使用yt-dlp下载全网视频

仓库地址
Waiting for api.github.com...
我练习项目的地址
Waiting for api.github.com...
点击右下角的release
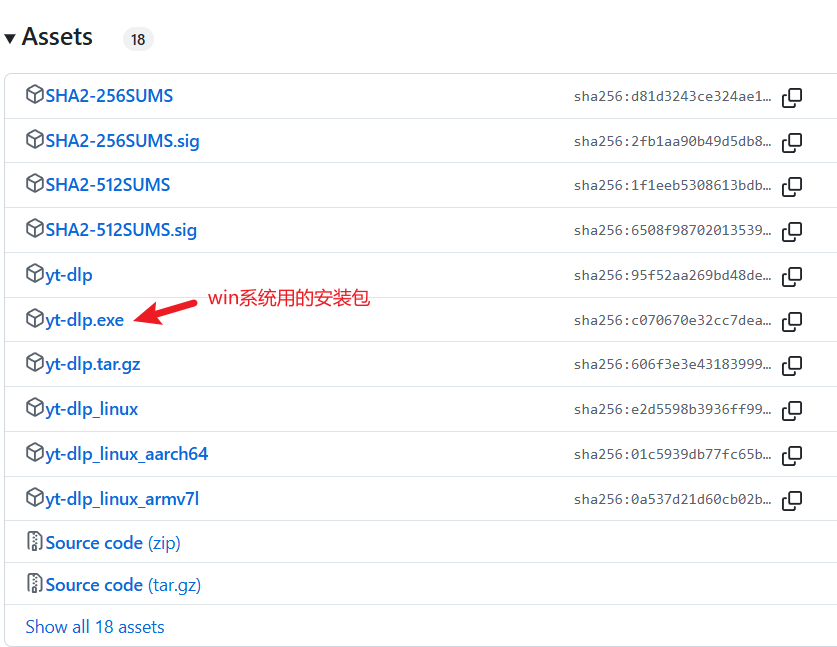
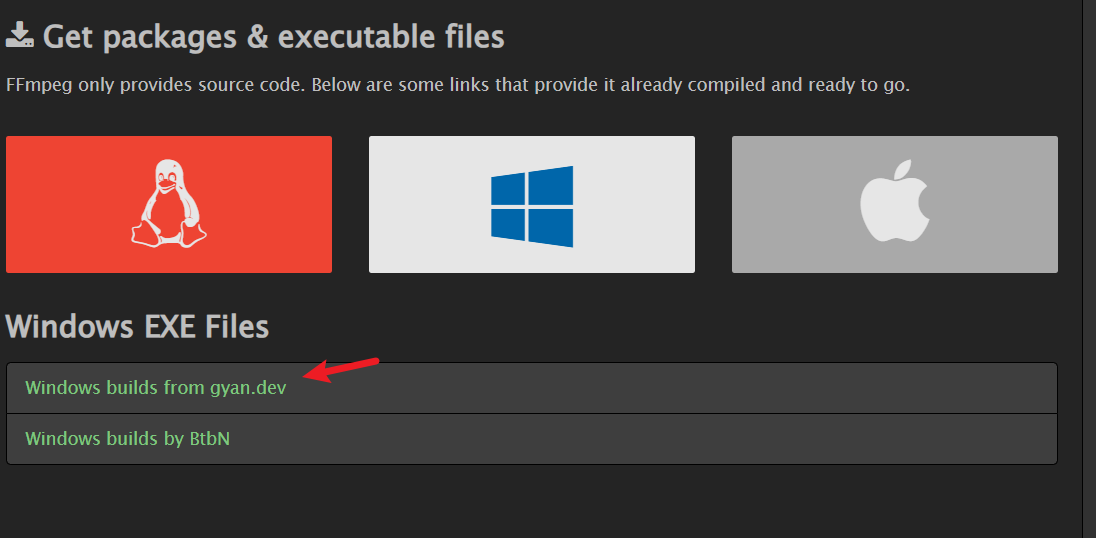
除此之外,还需下载ffmpeg插件

解压出来后,需要这两个文件
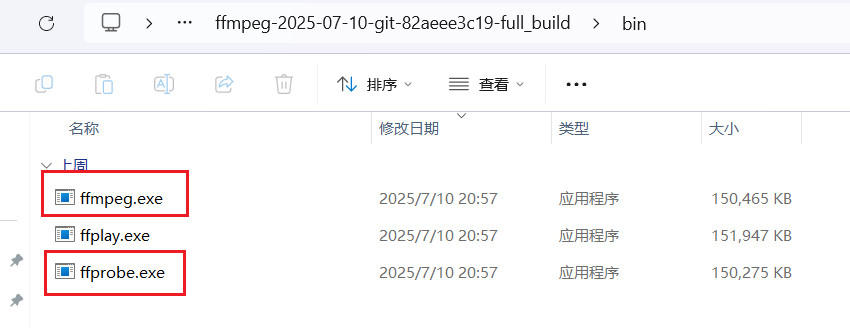
随后,新建一个文件夹,文件夹下有这三个文件yt-dlp ffprobe ffmpeg
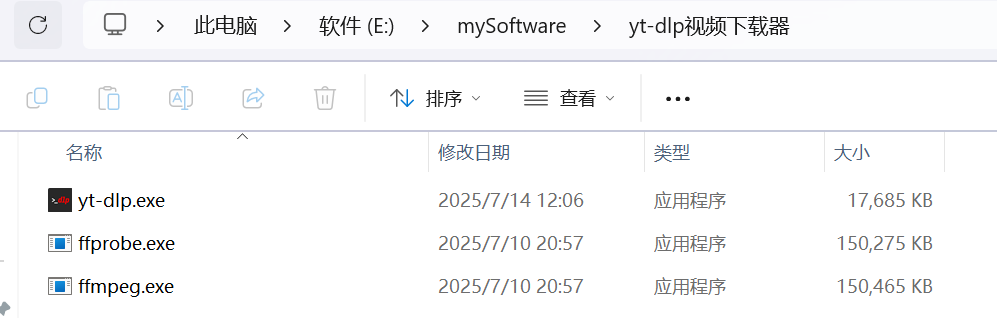
然后设置下这个文件夹的环境变量path,这样的话我们在哪里都能通过命令运行yt-dlp
测试下载bilibili视频
在你想放置下载视频的文件夹下打开cmd,输入命令yt-dlp+想下载的视频链接
yt-dlp https://www.bilibili.com/video/BV1sg411Y7n7/?spm_id_from=333.337.search-card.all.click&vd_source=8d3ddbf2d0edec4feaea7e750337df94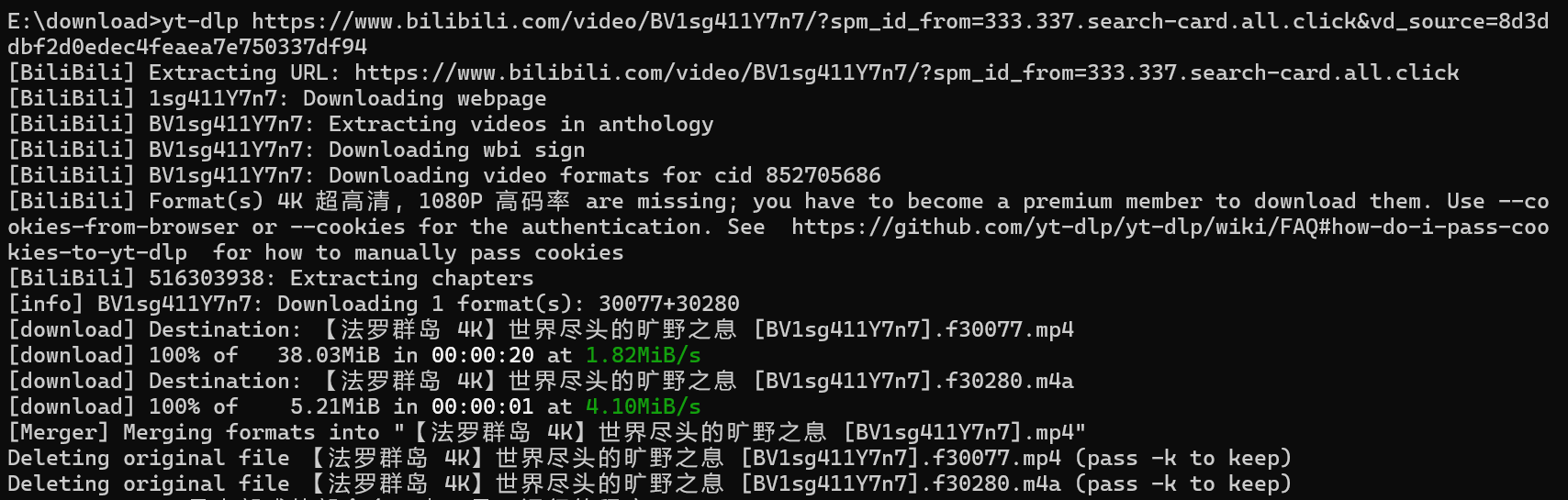
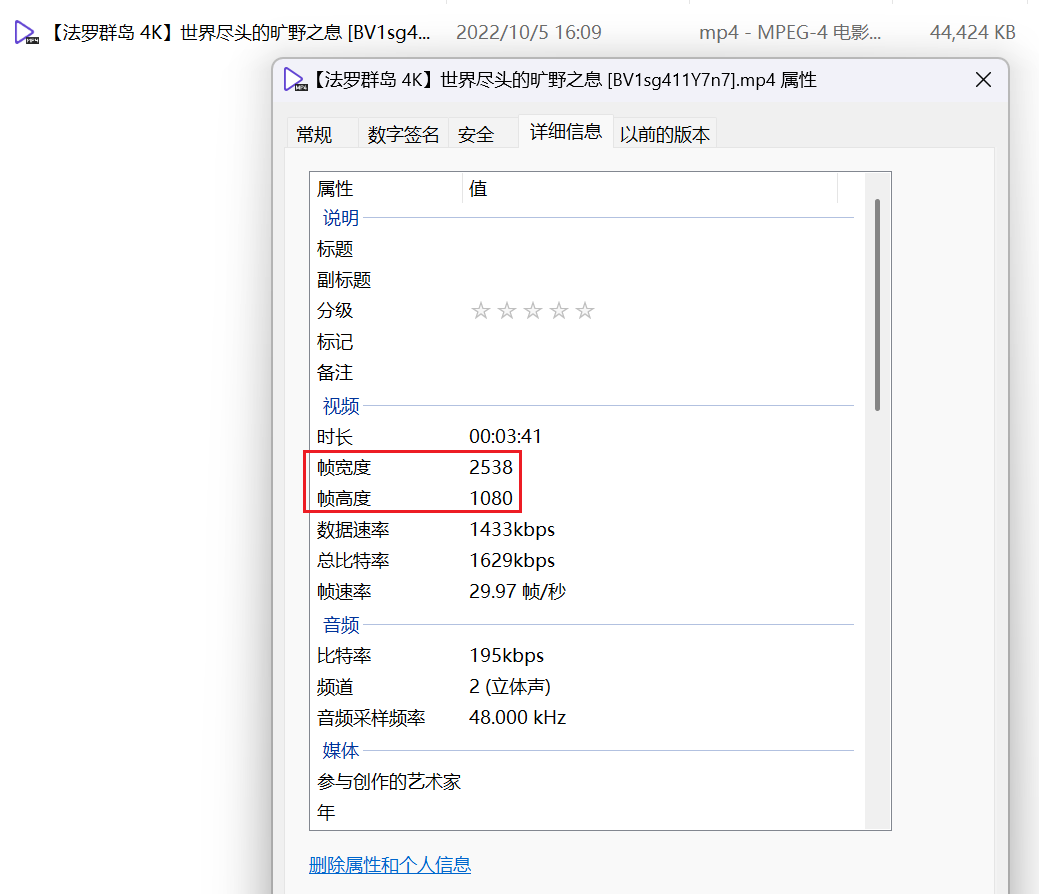
可以看到视频已经下载下来了,但是4k的视频下载下来只有
2k,yt-dlp还可以传一个cookie参数,用来提取用户登录cookie,从而下载最高清晰度的视频
测试下载油管视频
yt-dlp https://www.youtube.com/watch?v=5LxsViMm25o&list=PLTtnfaUimdLgRaBMnVe7iyctHbMTA4RGg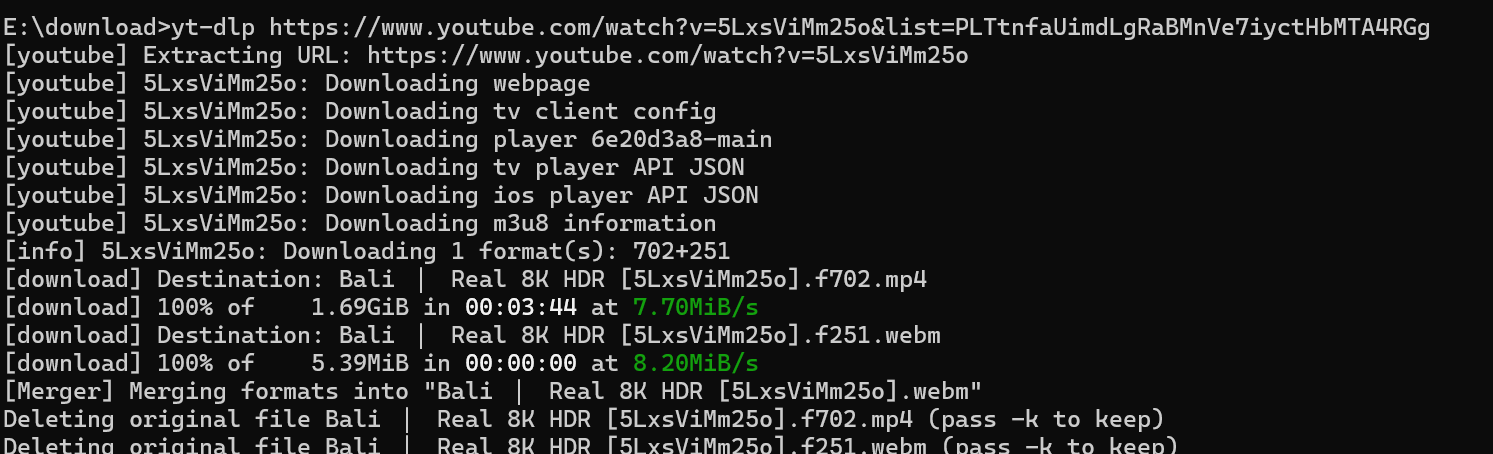
也是可以下载下来并正常播放的
传入cookie参数来下载
在传入之前我们需要安装一个浏览器插件

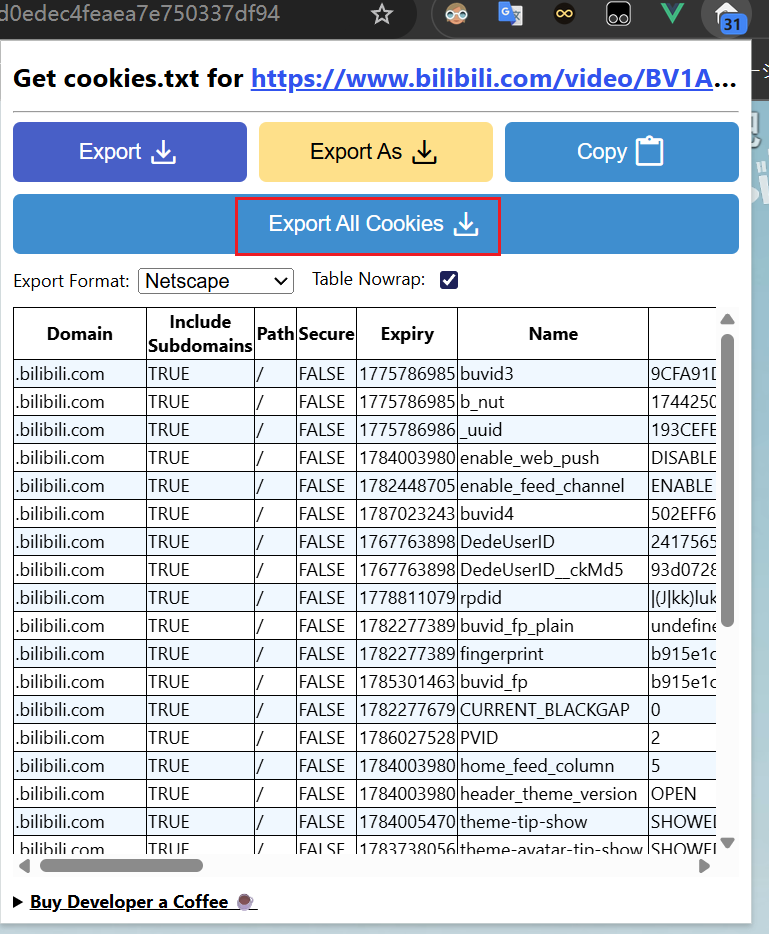
然后我们测试,把b站网页上所有的cookie下载下来
cookie在这里可以理解为下载高清视频的凭证
yt-dlp --cookies cookies.txt https://www.bilibili.com/video/BV1sg411Y7n7/?spm_id_from=333.337.search-card.all.click&vd_source=8d3ddbf2d0edec4feaea7e750337df94这里注意,把cookies.txt文件放在运行cmd的当前目录下

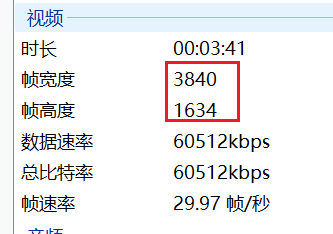
也是可以看到视频帧率变成了4k
自定义输出文件名
-o "%(title)s.%(ext)s"上面的代码表示的是用视频标题名.视频文件类型名的形式保存,现在测试一下
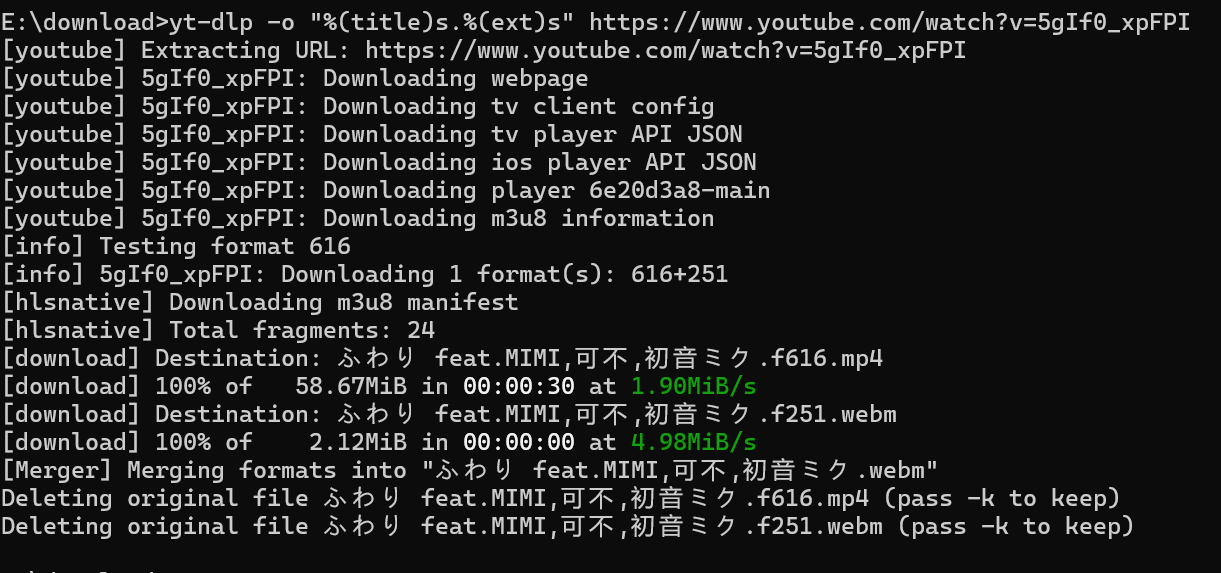
用python脚本下载
import yt_dlp
def download_video(url, output_path, cookie_file=None): """ 下载指定URL的视频并保存到指定目录
参数: url (str): 视频页面的URL地址 output_path (str): 用于存储下载视频的本地路径 cookie_file (str, optional): 包含cookies信息的文件路径,用于需要登录验证的网站. 默认为None.
返回: None: 函数不返回任何值 """ ydl_opts = { # 'format': 'bestvideo+bestaudio/best', 'outtmpl': output_path + '%(title)s.%(ext)s', }
if cookie_file: # 启用cookie支持以实现身份验证功能 ydl_opts['cookiefile'] = cookie_file
with yt_dlp.YoutubeDL(ydl_opts) as ydl: # 使用yt_dlp库创建下载管理器并开始下载视频 ydl.download([url])
if __name__ == "__main__": video_url = "https://www.youtube.com/watch?v=36LsS8T5RHE" output_directory = "./downloads/" cookie_file = "" # 替换为你的cookie文件路径 download_video(video_url, output_directory)还有一个爬取某个网页的所有cookies代码
from selenium import webdriverfrom selenium.webdriver.chrome.options import Optionsimport timeimport jsonfrom datetime import datetime
def get_cookies_with_selenium(url): """ 使用selenium获取完整的cookies """ options = Options() options.add_argument('--headless') # 无头模式,可选 driver = webdriver.Chrome(options=options)
try: driver.get(url) time.sleep(3) # 等待页面加载完成 cookies = driver.get_cookies() return cookies finally: driver.quit()
def save_cookies_to_netscape(cookies, filename="cookies.txt"): """ 将cookies保存为Netscape格式 """ with open(filename, 'w', encoding='utf-8') as f: f.write("# Netscape HTTP Cookie File\n") f.write("# http://curl.haxx.se/rfc/cookie_spec.html\n") f.write("# This is a generated file! Do not edit.\n\n")
for cookie in cookies: # 格式:domain flag path secure expiry name value domain = cookie.get('domain', '') flag = 'TRUE' if domain.startswith('.') else 'FALSE' path = cookie.get('path', '/') secure = 'TRUE' if cookie.get('secure', False) else 'FALSE' expiry = str(int(cookie.get('expiry', 0))) if cookie.get('expiry') else '0' name = cookie.get('name', '') value = cookie.get('value', '')
line = f"{domain}\t{flag}\t{path}\t{secure}\t{expiry}\t{name}\t{value}\n" f.write(line)
if __name__ == '__main__': print("请输入url:") url = input() print("请输入cookies文件名(默认:cookies.txt):") filename = input().strip() or "cookies.txt"
cookies = get_cookies_with_selenium(url) save_cookies_to_netscape(cookies, filename) print(f"成功导出 {len(cookies)} 个cookies到 {filename}")用python脚本也能下载,不过有个很大的问题
NOTE下载多了,会被视频网站阻止,得过一段时间才能恢复
还有一点,运行时文件夹内必须包含下面三个文件
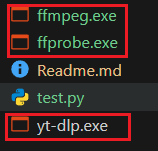
使用yt-dlp下载全网视频
https://yao-jiaye.github.io/posts/github仓库_yt-dlp/